A reinforcement learning approach
It’s time for another regime-shifting, so how did you adapt? Market neutral strategies rely on pairs trading, but how do you identify the hot new pairs while Covid-19 is sweeping across the world? Marshall Chang, Founder and CIO, A.I. Capital Management, shows us how his company leveraged reinforcement learning over the last two years and shares what his results are.
Pairs trading is the foundation of market neutral strategy, which is one of the most sought-after quantitative trading strategies because it does not profit from market directions, but from the relative returns between a pair of assets, avoiding systematic risk and the Random Walk complexity. The profitability of market neutral strategies lies within the assumed underlying relationship between pairs of assets. However, when such relationships no longer withhold, often during volatile regime-shifting times like this year with Covid-19, returns generally diminish for such strategies. In fact, according to HFR (Hedge Fund Research, Inc.), the HFRX Equity Hedge Index, by the end of July 2020, reported a YTD return of -9.74%; its close relative, the HFRX Relative Value Arbitrage Index, reported a YTD return of -0.85%. There is no secret that for market neutral quants, or perhaps any quants, the challenge is not just to find profitable signals, but more in how to quickly detect and adapt complex trading signals during regime-shifting times.
Within the field of market neutral trading, most research has been focusing on uncovering correlations and refining signals, often using proprietary alternative data purchased at high costs to find an edge. However, optimisation of capital allocation at trade size and portfolio level is often neglected. We found that lots of pair trading signals, though complex, still utilises fixed entry thresholds and linear allocations. With the recent advancement of complex models and learning algorithms such as deep reinforcement learning (RL), these class of algorithm is yearning for innovation with non-linear optimisation.
To address the detection and adaptation of pair trading strategies through regime shifting times, our unique approach is to solve trade allocation optimisation with sequential agent-based solution directly trained on top of existing signal generalisation process, with clear tracked improvement and limited overhead of deployment.
Internally named as AlphaSpread, this project demonstrates RL sequential trade size allocation’s ROI (return on investment) improvement over standard linear trade size allocation on 1 pair spread trading of US S&P 500 equities. We take the existing pair trading strategy with standard allocation per trade as baseline, train RL allocator represented by a deep neural network model in our customised Spread Trading Gym environment, then test on out-of-sample data and aim to outperform baseline ending ROI.
Specifically, we select co-integrated pairs based on their stationary spreads our statistical models. Co-integrated pairs are usually within the same industry, but we also include cross sectional pairs that show strong co-integration. The trading signal are generated by reaching pre-defined threshold of z-score on residues predicted by the statistical model using daily close prices. The baseline for this example allocates fixed 50% of overall portfolio to each trading signal, whereas the RL allocator output 0-100% allocation for each trading signal sequentially based on current market condition represented by a lookback of z-score.
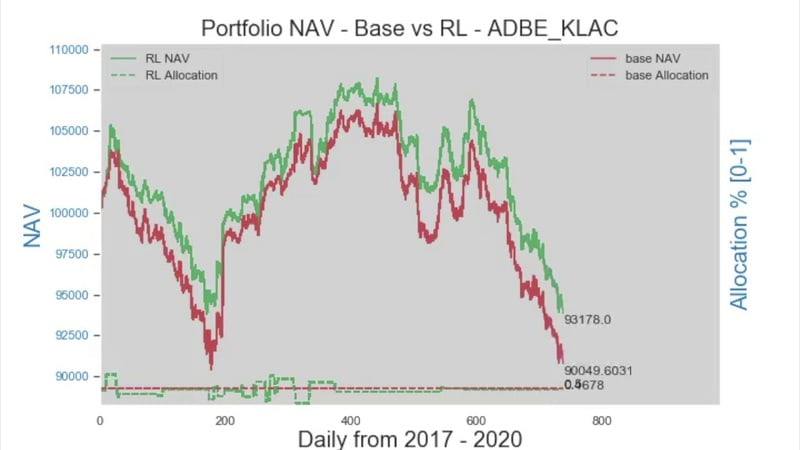
AlphaSpread - In the video, the red NAV is a signal’s performance into the Covid months, the green one is the same strategy with our RL allocator. We learned that our RL agent can pick up regime shifts early on and allocate accordingly to avoid huge downturns.
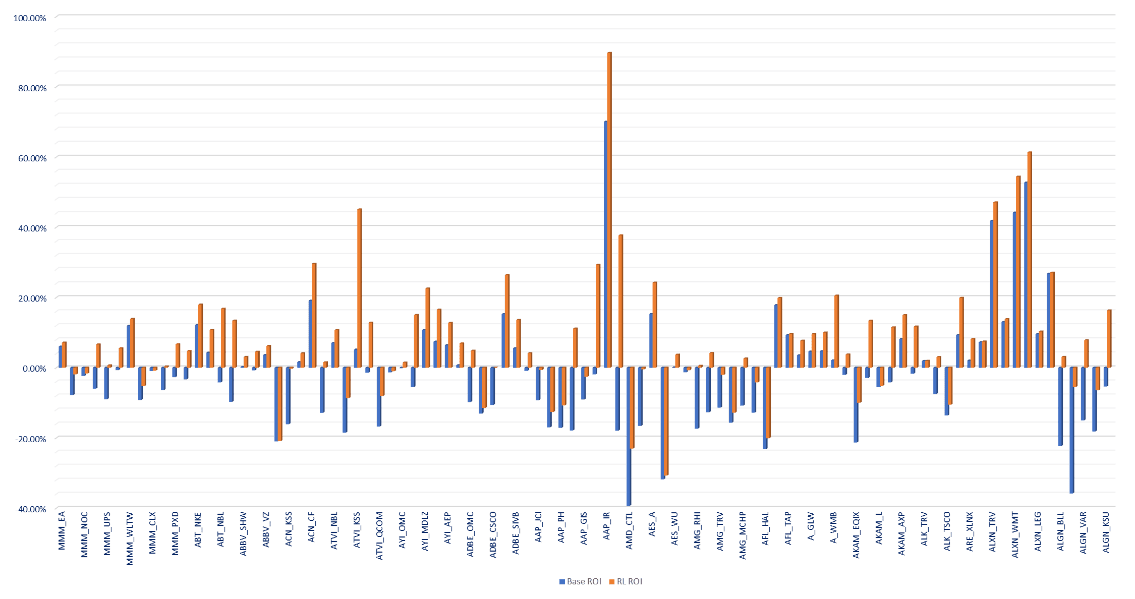
We summarise our RL approach’s pairs trading ROI against baseline linear allocation for 107 US equity pairs traded. The ROI is calculated with ending NAV of testing period against each pairs’ $100,000 starting capital. The result is from back-testing on out-of-sample data between 2018 to early 2020. The RL allocators are trained with data between 2006 and 2017. In both cases, fees are not consider in the testing. We have achieved on average 9.82% per pair ROI improvement over baseline approach, with maximum of 55.62% and minimum of 0.08%.
In other words, with limited model tuning, this approach is able to result in generalised improvement of ROI through early detecting of regime-shifting and the accordingly capital allocation adaptation by the RL allocator agent.
A snapshot of pair trading strategies’ ROI, comparing base allocation and RL allocation
The goal of this project is to demonstrate out-of-sample generalisation of the underlying improvements on a simple one-pair trading signals, hence providing guidance on adapting such methodology on large scale complex market neutral strategies. Below is a discussion of the three goals we set out to achieve in this experiment.
This RL framework consists of customised pairs trading RL environments used to accurately train and test RL agents, RL training algorithms including DQN, DDPG and Async Actor Critics, RL automatic training roll out mechanism that integrates memory prioritised replay, dynamic model tuning, exploration/ exploitation and etc., enabling repeatability for large datasets with minimum customisation and hand tuning. The advantage of running RL compared with other machine learning algorithm is that it is an end-to-end system from training data generalisation to reward function design, model and learning algorithm selection, and output a sequential policy. A well-tuned system requires minimum maintenance and the retraining/ readapting of models to new data is done in the same environment.
Under the one-pair trading example, the pairs’ co-integration test and RL training were done using data from 2006 and 2017, and then trained agents run testing from 2018 to early 2020. The training and testing data split are roughly 80:20. With RL automatic training roll out, we can generalise sustainable improvements over baseline return for more than 2 years across hundreds of pairs. The RL agent learns to allocate according to the lookback of z-scores representing the pathway of the pairs’ co-integration as well as volatility and is trained with exploration/ exploitation to find policy that maximise ending ROI. Compared with traditional supervised and unsupervised learning with static input-output, RL algorithms has built-in robustness for generalisation in that it directly learns state-policy values with a reward function that reflects realised P/L. The RL training targets are always non-static in that the training experience improves as the agent interacts with the environment and improves its policy, hence the reinforcement of good behaviour and vice versa.
Train and deploy large scale end-to-end deep RL trading algorithms is still in its infancy in quant trading, but we believe it is the future of alpha in our field, as RL has demonstrated dramatic improvement over traditional ML in the game space (AlphaGo, Dota, etc.). This RL framework is well-versed to apply to different pair trading strategies that is deployed by market neutral funds. With experience running RL system in multiple avenues of quant trading, we can customise environment, training algorithms, and reward function to effectively solve unique tasks in portfolio optimisation, powered by RL’s agent based sequential learning that traditional supervised and unsupervised learning models cannot achieve.
We first run a linear regression on both assets’ past look back price history (2006-2017 daily price), then we do OLS test to obtain the residual, with which we run unit root test (Augmented Dickey-Fuller test) to check the existence of co-integration. In this example, we set the p-value threshold at 0.5% to reject unit root hypothesis, which results in a universe of 2794 S&P 500 pairs that pass the test.
Next phrase is how we set the trigger conditions. First, we normalise the residual to get a vector that follows assumed standard normal distribution. Most tests use mean plus two standard deviations as the entrance/exit threshold, which is often hard to trigger. To generate enough trading for each pair, we set our threshold at mean plus one standard deviation. After normalisation, we obtain a white noise follows N(0,1), and set +/-1 as the threshold. Overall, the signal generation process is very straight forward. If the normalised residual gets above or below threshold, we long the bearish one and short the bullish one, and vice versa. We only need to generate trading signal of one asset, and the other one should be the opposite direction.
The RL training regimes start with running an exploration to exploitation linear annealed policy to generate training data by running the training environment, which in this case runs the same 2006-2017 historical data as with the co-integration. The memory is stored in groups of
State, Action, Reward, next State, next Action (SARSA)
Here we use a mixture of DQN and Policy Gradient learning target, in that our action outputs are continuous (0-100%) yet sample inefficient (within hundreds of trades per pair due to daily frequency). Our training model updates iteratively with
Q(State) = reward + Q-max (next States, next Actions)
Essentially, RL agent is learning the q value of continuous-DQN but trained with policy gradient on the improvements of each policy, hence avoiding the sample inefficiency (Q-learning is guaranteed to converge to training global optimal) and tendency to stuck in local minimum too quickly (avoiding all 0 or 1 outputs for PG). Once the warm-up memories are stored, we train the model (in this case is a 3-layer dense net outputting single action) with the memory data as agent continues to interact with the environment and roll out older memories.
Marshall Chang is the founder and CIO of A.I. Capital Management, a quantitative trading firm that is built on deep reinforcement learning’s end-to-end application to momentum and market neutral trading strategies. The company primarily trades the foreign exchange markets in mid-to-high frequencies.
Sutton RS, Barto AG. Reinforcement learning: An introduction. MIT press; 2018.
HFRX® Indices Performance Tables. (n.d.). Retrieved August 03, 2020, from https://www.hedgefundresearch.com/family-indices/hfrx