By Anne Richelle and Moritz von Stosch
by Anne Richelle and Moritz von Stosch
High-throughput technologies have transformed the biotechnology industry. The amount of data they generate is at least a hundred times higher now than it was two decades ago, primarily because of the rise of “-omic” technologies. As in many other industries, the biopharmaceutical sector entered the era of big data the day that high-throughput analytics were routinely implemented in experimental research.
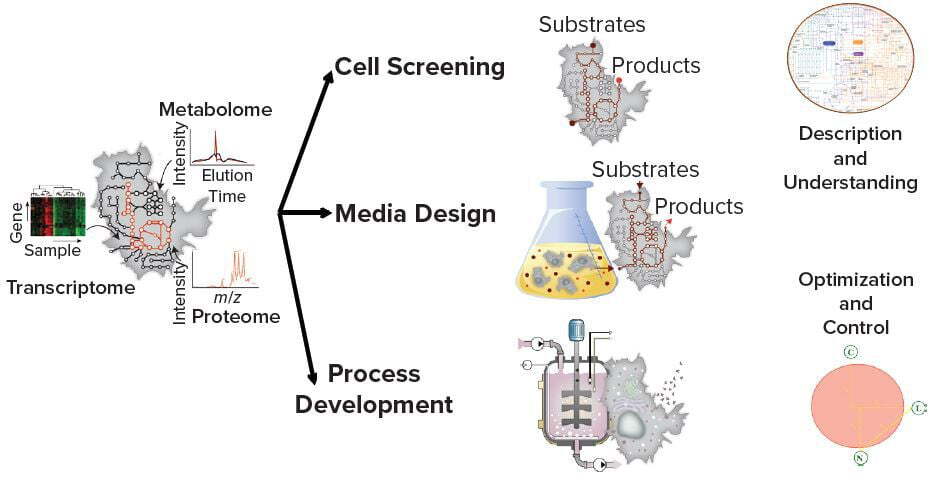
Figure 1: Systems biology tools can facilitate upstream research activities (bioreactor imagery: https://commons.wikimedia.org/wiki/User:Rocket000/ SVGs/Chemistry#/media/File:Bioreactor_principle.svg)
Big data refers to “datasets with sizes beyond the ability of commonly used software tools to capture, curate, manage, and process data within a tolerable elapsed time” (1). Technically, scientists from the field agree that big data is defined by specific attributes, the so-called 4V model: volume (scale of data), variety (different forms of data), velocity (analysis of streaming data), and veracity (uncertainty of data) (2). Considering these definitions, is the size of the datasets that biopharmaceutical researchers handle truly the problem?
Compared with other research sectors, the biopharmaceutical industry generates low amounts of data. That is mainly because of the costs associated with experimental procedures for producing good-quality data, but also because the industry’s conservative mindset restricts dataset use to proprietary generators. Thus, experiments established in the context of a biopharmaceutical project rarely are big data. The size of datasets might begin to be a problem if data across projects or across the industry were considered together. However, even if the intellectual propriety burden of sharing bioprocessing data is assuaged, such databases are not easily accessible in machine-readable format. Furthermore, the lack of standardization among such databases makes them difficult to exploit systematically without extensive processing. Unfortunately, that statement is many times also valid for data generated by different research teams within one company because their data can be corrupted by the heterogenous environment (3) and potential hidden factors (4).
Although data have been generated for decades in the biopharmaceutical sector, the precarity of data management solutions in many companies renders exploitation of those data almost impossible. This consideration of historical bioprocess data also raises the question of data “longevity.” Indeed, data support and experimental techniques are evolving continuously, making it difficult to extract data from obsolete storage supports (e.g., floppy disks) and to compare data generated using different generations of experimental technologies — such as serial analysis of gene expression (SAGE) compared with RNA sequencing (RNAseq). Thus, the main problem with biopharmaceutical datasets is not related to their size but more likely to the time researchers require to handle those data, including integration of diverse data sources and extraction of meaningful information from such integrated datasets.
Machine Learning As a Discovery Driver for Large Datasets
Machine learning (ML) is a powerful tool that helps researchers extract information from data (5). ML is expected to be a significant tool in the bioprocess industry (6). Over the past few years, biomanufacturers have invested greatly in the development of such data-driven methods and in data capturing and management solutions.
Increasing attention to those approaches has led to researchers questioning the ability of large datasets to “speak for themselves” (7). Many researchers have demonstrated that “big structure” is full of spurious correlations because of noncausal coincidences, hidden factors, and the nature of “big randomness.” With a deluge of new ML tools, some researchers point to the complexity of algorithms developed, making it impossible to inspect all parameters or to reason fully about how inputs have been manipulated (8).
Although we can highlight only the invaluable potential impact of such techniques, it is important to keep in mind that ML tools also can turn out to be “fool’s gold.” Specifically in biotechnology, black-box approaches will support rapid development of powerful predictive models if a problem is concise and well structured. But their ability to provide biologically relevant explanations of predicted results from a given dataset might be somewhat compromised. To prevent such pitfalls, the empirical knowledge that has been accumulated over decades of biological research should be integrated as a baseline to guide such data-driven methods.
Systems Biology Tools: Beyond Drug Discovery and Cell Design
Systems biology tools are model-based approaches used for the description of complex biological systems. They enable the coherent organization of large datasets into biological networks, and they provide insights on biological systems that in vivo experiments alone cannot (9). In the context of metabolic processes, genome-scale metabolic network models (GEMs) are used as platforms for -omics data integration and interpretation by linking the genotype of an organism and the phenotypes it can exhibit during an experiment. Such networks can be used as libraries for developing cell- and tissue-specific models. Because some enzymes are active only in specific environments, context-specific extraction methods can be used for tailoring genome-scale models based on -omic data integration. Several algorithms have been developed to recapitulate the metabolism of specific cell and tissue types, providing useful insights into their metabolism under such specific conditions (10). Biological networks then can be used as frameworks to integrate diverse data sources and subsequently extract meaningful information. So a GEM can be described as not only a network of reactions, but also as an interconnected map of cellular functions.
Systems biology tools have proven to be invaluable at the level of preclinical research such as for designing new drugs by informing upon target selection (11) or for engineering cells by rewiring their metabolism toward the production of a product (12). But such approaches can be used for much more. For example, they could be applied at the industrial level in the field of upstream activities, including process design, monitoring and control, lowering experimental effort, and increasing process robustness and intensity (Figure 1).
Such efforts are expected to facilitate greatly the implementation of the quality by design (QbD) paradigm and process analytical technology (PAT) initiatives. Based on the potential predictive power of such mechanistic approaches, you might be surprised that improved bioprocess performance still is achieved mainly by semiempirical media and bioprocess optimization techniques (e.g., media screening and statistical design of experiments, DoE).
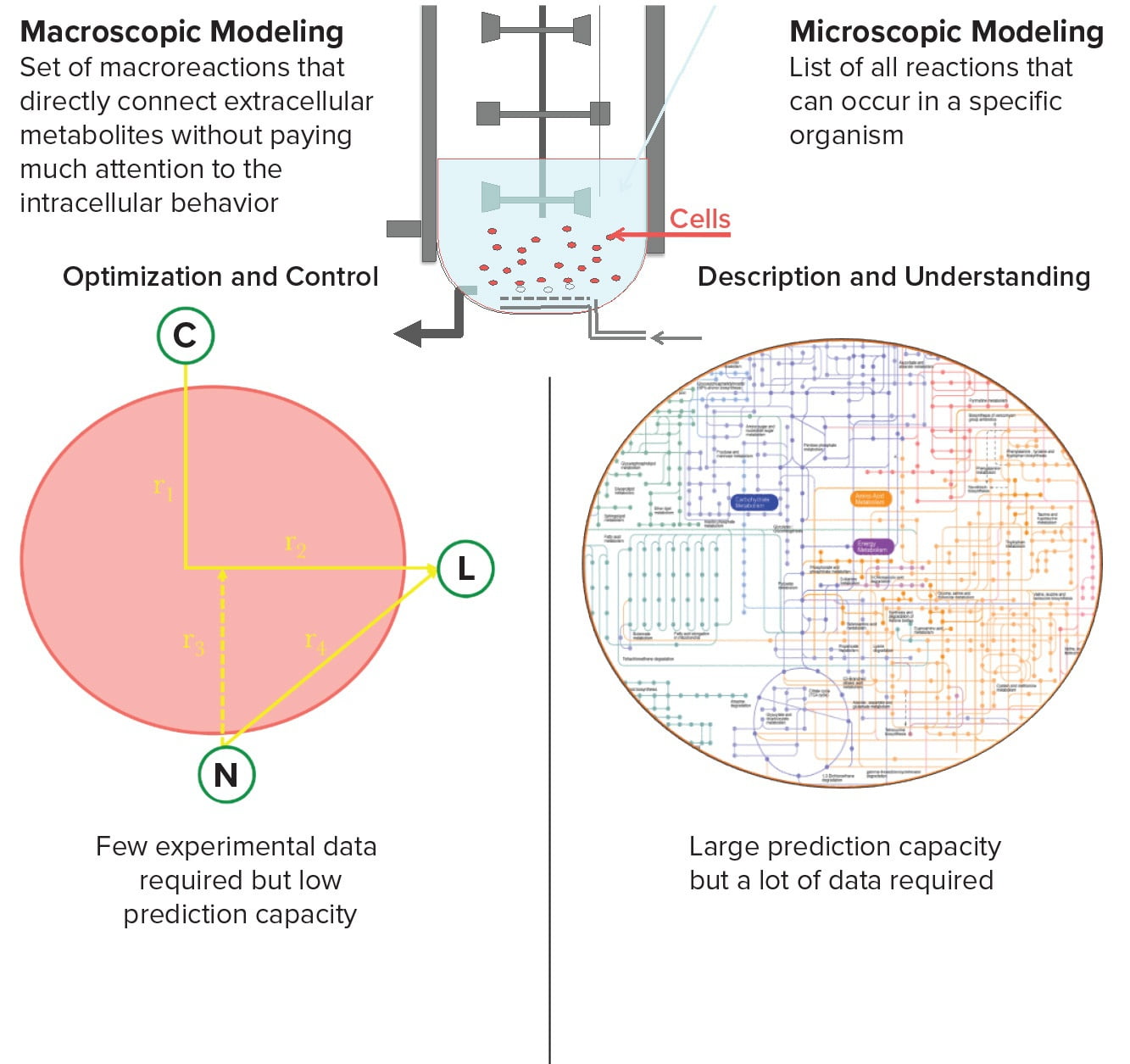
Current restricted applications of such systems-biology tools are caused by the lack of a systemic workflow to generate predictive models for upstream activities from biological networks. The complexity and structure of predictive mechanistic models mainly are defined by their final purposes (13) (Figure 2). A model with the objective of describing as accurately as possible the mechanisms underlying a process operation certainly will have a greater structural complexity than a model developed for optimization of that process.
It is important to note that the dynamics related to a process operation can vary in complexity themselves. Obviously, it is much easier to model the operation of a draining sink than to model the operation of a combustion engine, for example. So one part of a model’s structural complexity also will mirror the complexity of the system being studied.
References 1 Big Data. Wikipedia; https://en.wikipedia.org/wiki/Big_data.
2 The Four V’s of Big Data. IBM, 2013; http://www.ibmbigdatahub.com/infographic/four-vs-big-data.
3 Bühlmann P, van de Geer S. Statistics for Big Data: A Perspective. Stat. Prob. Lett. 136, 2018:37-41; doi:10.1016/j.spl.2018. 02.016.
4 Liu Y, et al. Multiomic Measurements of Heterogeneity in HeLa Cells Across Laboratories. Nat. Biotechnol. 37, 2019: 314–322; doi:10.1038/s41587-019-0037-y.
5 Witten IH, et al. Data Mining: Practical Machine Learning Tools and Techniques, 4th ed. Morgan Kaufmann Publishers Inc: Cambridge, MA, 2016.
6 Manyika J, et al. Big Data: The Next Frontier for Innovation, Competition, and Productivity. McKinsey Global Institute: New York, NY, 2011.
7 Calude CS, Longo G. The Deluge of Spurious Correlations in Big Data. Found. Sci. 22(3) 2016: 595–612.
8 Riley P. Three Pitfalls to Avoid in Machine Learning. Nature 572(7767) 2019: 27–29.
9 Bordbar, et al. Constraint-Based Models Predict Metabolic and Associated Cellular Functions. Nat. Rev. Gen. 15(2) 2014: 107–120; doi:10.1038/nrg3643.
10 Opdam S, et al. A Systematic Evaluation of Methods for Tailoring Genome-Scale Metabolic Models. Cell Sys. 4(3) 2017: 318–329; doi:10.1016/j.cels.2017.01.010.
11 Schmidt BJ, Papin JA, Musante CJ. Mechanistic Systems Modeling to Guide Drug Discovery and Development. Drug Discovery Today 18(3–4) 2013: 116–127.
12 Mardinoglu A, et al. Genome-Scale Metabolic Modelling of Hepatocytes Reveals Serine Deficiency in Patients with Nonalcoholic Fatty Liver Disease. Nat. Commun. 5, 2014: 3083.
13 Walter E, Pronzato L. Identification of Parametric Models from Experimental Data. Springer: London, 1997.