Jamil Mina, Red Hat, explores
Site Reliability Engineering (SRE), initially popularized by Google, is an operating model to solve complex operational issues associated with scalable and highlighly reliable data centre sites. As a development practice, and founded in engineering, SRE has been a method helpful to align business objectives with both technical development and operations goals.
Public cloud providers care very much about site reliability because they are in the business of providing reliable compute and storage services - if the site is down they lose money. In order to minimize site downtime and have accountability for reliability, service deployment and support activities are ingrained in the application development role - you build it, you support it.
Financial Institutions (FIs), on the other hand, are in the business of trust. Trust from customers that their funds are safe and available when and how they need. To inspire this trust, banks must minimize risk and provide services that are secure, reliable, resilient and always available. With the accelerating pace of digital banking service adoption, the need to scale reliable services has never been greater.
While web site providers and FIs share a similar reliability objective, a key difference is that FIs are held to regulatory compliance requirements which necessitate the segregation of responsibility - to minimize and eliminate as much operational and financial risk as possible. Imposed by Basel, Sarbanes-Oxley, and OSFI, the regulators state that sufficient controls must be implemented to separate functions and ensure that no single function has end to end responsibility of a single process which could compromise financial transactions or cause data loss. So, if you build it - you can’t support it.
Bridging this gap is a new concept, ‘Service Reliability Engineering’ (SvRE), which takes into consideration financial service regulatory requirements as part of providing a highly scalable and reliable digital banking service.
Within DevOps practices FIs have already implemented controls to separate development and operational support activities as part of continuous delivery pipelines. These pipelines have security, compliance and segregation of responsibilities built-in. Controls are implemented by limiting production access for developers and not giving operations teams access to source code. This removes the capabilities of malicious developers to run nefarious code in production and then covering their tracks, and for operations staff to modify the code as part of any malevolent activity.
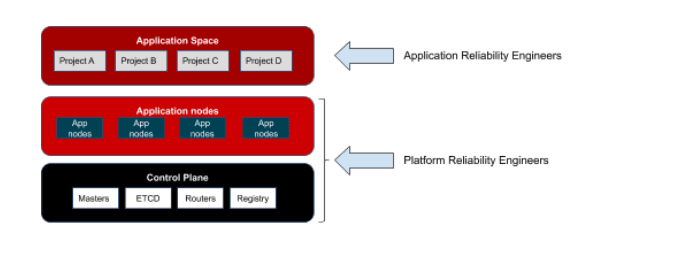
Within SvRE, the application (the functional part of the service) needs to be separated from the platform (the set of technologies that the application is dependent on to run) in order to separate the responsibility of building and supporting services.
Alas, typically, FIs have four distinct organizations involved in the delivery of applications:
Each of these teams have a distinct role to deliver applications, however, the manual hand overs and complex ticketing systems used makes it hard to identify the specific owner associated with the reliability of a particular service. Oftentimes, it is the System Support Teams that end up holding the reliability bag, without any understanding of the application or how it interacts with the underlying platform.
In a smaller firm, with a mono-application where a whole system is designed to support one function, it is easy to have deep skills in the applications and the underlying systems - so this is less of an issue. However, in large FIs where there are complex systems and dependencies, it is not easy to have people that are skilled in the platform, the underlying infrastructure, and the application required to separate the division of responsibilities needed for SvRE due diligence.
Our recommendation is to establish Application Recovery Engineers (ARE) and Platform Recovery Engineers (PRE) practices. Developing strong expertise in application recovery and platform availability mimic the industry definition of SRE organizational roles and responsibilities, with members having the responsibility for application reliability and platform reliability, respectively. By adopting service level objectives (SLO) and error budgets as a common measure that governs service reliability, AREs and PREs collaborate together to achieve the organizational metrics that balance market agility and reliability - providing the necessary framework for measuring and tolerating allowable risk. This would help promote continuous feedback processes across the teams (metrics, weekly feedback sessions, joint solutioning, testing, common automation frameworks, etc.), and would help mitigate the risk associated with diverging from their essential function, securing the reliability of application services. As a best practice, you must limit the SvRE to a small set of critical applications, specifically those which are visible to customers.
Teams are best supported by technology that enforces the segregation of responsibility requirement. As illustrated, a platform that can isolate the application space (where specific projects reside along with their configurations), from the application nodes (where containers run), from the control plane of the platform, provides a reliable way to separate concerns application reliability engineers and platform reliability engineers may face in assuring their commitment to organizational mandates. Moreover, when the technology provides the flexibility to run any project, or containers in any control plan - whether behind the institutions firewalls or in one or more cloud provider sites, confidence can be had that the segregation of responsibilities is retained because it is built-in to a consistent platform.
Addressing the needs for observability, security, application and infrastructure immutability with a secure pipeline that includes release capabilities, the right platform technology can help manage the manual, repetitive, automatable, tactical tasks that provide enduring value that scale linearly as a service grows . In financial institutions, like most organizations, an operational shift is happening - one that promotes proactive prevention, and indeed, isn’t that what reliability is all about.